In this notebook, we’re going to showcase how to run the powerful Flux model on a machine requiring only 8GB of GPU memory. This leverages the technique of quantization, which means shrinking down the size of a model significantly with minimal impact on the performance.
This is based on the amazing work by the 🤗 Diffusers team, and this tweet by Aritra (go give them a follow). Credits to them!
Quick intro to Flux
Flux is an impressive text-to-image (and image-to-image) model by Black Forest Labs, the creators of Stable Diffusion. It can be seen as the successor of Stable Diffusion, and incorporates many advancements in the field, including:
- the use of 2 pre-trained text encoders (CLIP and T5)
- the use of a Transformer-based DiT model for denoising
- the use of a variational auto-encoder (VAE) to perform the denoising in a latent space, rather than in pixel space (similar to Stable Diffusion).
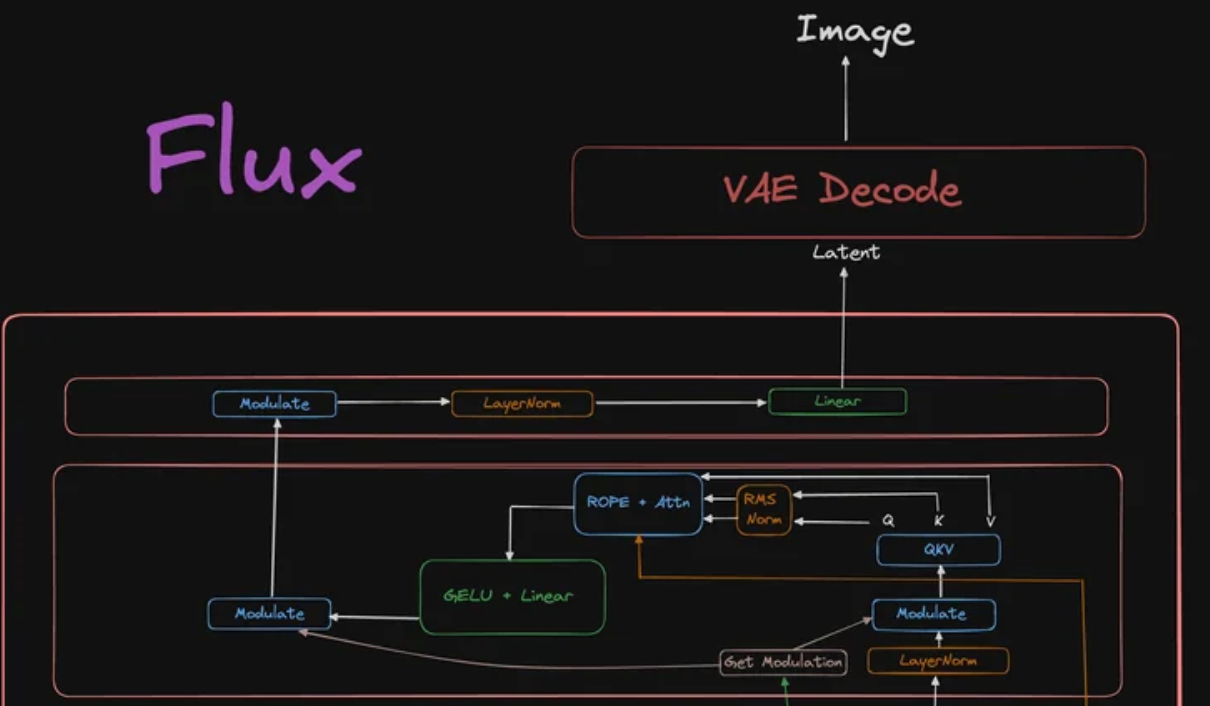
Flux model architecture. Taken from Reddit.
The use of 2 pre-trained text encoders (as seen at the bottom of the diagram) makes it a lot better at understanding prompts and rendering text within images.
The authors released various variants of Flux:
- Flux-Schnell, an open-source model available on Hugging Face (distilled from the larger variants).
- Flux-Dev, an open model available on Hugging Face, but with a non-permissive license
- Flux-Pro, a closed-source model only accessible via various APIs.
Set-up environment
Make sure to set your runtime to “GPU” (I’ve tested it on both NVIDIA T4 and NVIDIA L4 GPUs). You can check that a GPU is active by running the nvidia-smi command:
!nvidia-smi
Mon Oct 21 12:47:08 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 44C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
We first install the necessary 🤗 goodies. We need:
- Diffusers for the Flux model
- Transformers for the pre-trained text encoders
- Accelerate and BitsAndBytes to allow us to run this model on consumer hardware.
The main idea behind this notebook is quantization, which means shrinking down the size of a neural network’s parameters massively without big reductions in performance. In short, the parameters of a neural network can be stored in 32 bits (or 4 bytes) per parameter, 16 bits (or 2 bytes), or even lower like 8 bits or 4 bits (half a byte) per parameter.
By default, neural networks are often stored in 32 bits or 4 bytes per parameter (also called “full precision”), but in this notebook, we’re going to shrink it down to only 4 bits (or 0.5 bytes) per parameter. As we’ll see, the performance difference is negligible.
As Diffusers just added support for running giant models like Flux on consumer hardware (using BitsAndBytes’ quantization techniques), we install Diffusers from source here.
!pip install –upgrade -q transformers accelerate bitsandbytes
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.4/44.4 kB 1.3 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.9/9.9 MB 63.4 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 330.9/330.9 kB 22.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 122.4/122.4 MB 16.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.0/3.0 MB 82.8 MB/s eta 0:00:00
!pip install -q git+https://github.com/huggingface/diffusers
Installing build dependencies ... done Getting requirements to build wheel ... done Preparing metadata (pyproject.toml) ... done Building wheel for diffusers (pyproject.toml) ... done
Define Flush utility
First, we define a utility function which can be used to flush (clean up) the memory of the GPU.
import torch import gc defflush(): gc.collect() torch.cuda.empty_cache() torch.cuda.reset_max_memory_allocated() torch.cuda.reset_peak_memory_stats() flush()
/usr/local/lib/python3.10/dist-packages/torch/cuda/memory.py:343: FutureWarning: torch.cuda.reset_max_memory_allocated now calls torch.cuda.reset_peak_memory_stats, which resets /all/ peak memory stats. warnings.warn(
Load T5 text encoder in 4 bit
Next, it’s time to only leverage one of the 2 text encoders of Flux. Flux itself uses 2 text-encoders, based on CLIP and T5. This can be seen if you check the “Files and versions” tab of the Flux-dev model repository on the hub. It has 2 subfolders:
- “text_encoder” (which contains the weights of the CLIP model)
- “text_encoder_2” (which contains the weights of the T5 model).
Here, we only load the T5 pre-trained text encoder from the hub (hence the “text_encoder_2” subfolder), and load it in 4 bits.
This text encoder takes about 10GB in float32 (32 bits per parameter or full-precision), but as we load it in 4 bits per parameter, this takes 8 times less amount of memory, hence only 10/8 = 1.25GB of GPU memory.
from transformers import T5EncoderModel ckpt_4bit_id = “sayakpaul/flux.1-dev-nf4-pkg” text_encoder_2_4bit = T5EncoderModel.from_pretrained( ckpt_4bit_id, subfolder=”text_encoder_2″, )
text_encoder_2/config.json: 0%| | 0.00/1.27k [00:00<?, ?B/s]
Unused kwargs: ['_load_in_4bit', '_load_in_8bit', 'quant_method']. These kwargs are not used in <class 'transformers.utils.quantization_config.BitsAndBytesConfig'>. `low_cpu_mem_usage` was None, now set to True since model is quantized.
model.safetensors: 0%| | 0.00/6.33G [00:00<?, ?B/s]
Load Flux pipeline with T5 text encoder only
Next, we load the Flux pipeline from the hub, but as can be seen, we do not actually load the Transformer model nor the VAE (variational auto-encoder). We only equip it with the pre-trained text encoder from above, and are only going to use the pipeline for encoding the text prompt.
We also enable CPU offloading for the pipeline, which means that if some parameters are too large to be loaded onto the GPU, they will be sent to (“offloaded”) the CPU. Read more about how Accelerate handles this here.
from diffusers import FluxPipeline, FluxTransformer2DModel ckpt_id = “black-forest-labs/FLUX.1-dev” pipeline = FluxPipeline.from_pretrained( ckpt_id, text_encoder_2=text_encoder_2_4bit, transformer=None, vae=None, torch_dtype=torch.float16, ) pipeline.enable_model_cpu_offload()
model_index.json: 0%| | 0.00/536 [00:00<?, ?B/s]
Fetching 12 files: 0%| | 0/12 [00:00<?, ?it/s]
tokenizer/merges.txt: 0%| | 0.00/525k [00:00<?, ?B/s]
tokenizer/special_tokens_map.json: 0%| | 0.00/588 [00:00<?, ?B/s]
tokenizer_2/special_tokens_map.json: 0%| | 0.00/2.54k [00:00<?, ?B/s]
text_encoder/config.json: 0%| | 0.00/613 [00:00<?, ?B/s]
tokenizer/tokenizer_config.json: 0%| | 0.00/705 [00:00<?, ?B/s]
scheduler/scheduler_config.json: 0%| | 0.00/273 [00:00<?, ?B/s]
tokenizer/vocab.json: 0%| | 0.00/1.06M [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/246M [00:00<?, ?B/s]
spiece.model: 0%| | 0.00/792k [00:00<?, ?B/s]
tokenizer_2/tokenizer.json: 0%| | 0.00/2.42M [00:00<?, ?B/s]
tokenizer_2/tokenizer_config.json: 0%| | 0.00/20.8k [00:00<?, ?B/s]
Loading pipeline components...: 0%| | 0/5 [00:00<?, ?it/s]
You set `add_prefix_space`. The tokenizer needs to be converted from the slow tokenizers
Encode text prompt to get text embeddings
Next, we use the pipeline to encode a text prompt that we want the model to generate. Here we decide to generate an image for “a cute dog in paris photoshoot” 🙂 We basically send the text prompt through the T5 pre-trained text encoder to obtain text embeddings.
Next, we delete the pipeline and free up the GPU memory.
prompt = “a cute dog in paris photoshoot”with torch.no_grad(): print(“Encoding prompts.”) prompt_embeds, pooled_prompt_embeds, text_ids = pipeline.encode_prompt( prompt=prompt, prompt_2=None, max_sequence_length=256 ) pipeline = pipeline.to(“cpu”) del pipeline flush()
Encoding prompts.
/usr/local/lib/python3.10/dist-packages/torch/cuda/memory.py:343: FutureWarning: torch.cuda.reset_max_memory_allocated now calls torch.cuda.reset_peak_memory_stats, which resets /all/ peak memory stats. warnings.warn(
Now we have the text embeddings (both for all tokens, and a “pooled” version which can be seen as a summary of all the tokens)!
Let’s check their shape:
print(f”prompt_embeds shape: {prompt_embeds.shape}”) print(f”pooled_prompt_embeds shape: {pooled_prompt_embeds.shape}”)
prompt_embeds shape: torch.Size([1, 256, 4096]) pooled_prompt_embeds shape: torch.Size([1, 768])
The token embeddings (prompt_embeds) are of shape (batch_size, num_tokens, embedding_dimension). Since we only send one text prompt through the model, the batch size is 1. The text prompt is encoded into 256 tokens, each of which has a vector representation of size 4096.
The pooled vector representation (pooled_prompt_embeds) are of shape (batch_size, embedding_dimension) and is a vector of size 768.
We’ll use both the individual token embeddings as well as the pooled embeddings to condition the Flux model for generating an image.
Load pipeline in 4 bit
Now that we have obtained the text embeddings in a memory-efficient way, the idea will be to condition the Flux model on those.
Below, we load the Flux pipeline again, but this time, we do not need the text encoders anymore (since we already encoded our prompt above).
Instead, we only equip it with the pre-trained Transformer and the VAE. Again, we load both in 4 bits per parameter rather than 32 to make them run on consumer hardware.
transformer_4bit = FluxTransformer2DModel.from_pretrained(ckpt_4bit_id, subfolder=”transformer”) pipeline = FluxPipeline.from_pretrained( ckpt_id, text_encoder=None, text_encoder_2=None, tokenizer=None, tokenizer_2=None, transformer=transformer_4bit, torch_dtype=torch.float16, ) pipeline.enable_model_cpu_offload()
transformer/config.json: 0%| | 0.00/902 [00:00<?, ?B/s]
diffusion_pytorch_model.safetensors: 0%| | 0.00/6.70G [00:00<?, ?B/s]
Fetching 4 files: 0%| | 0/4 [00:00<?, ?it/s]
vae/config.json: 0%| | 0.00/820 [00:00<?, ?B/s]
diffusion_pytorch_model.safetensors: 0%| | 0.00/168M [00:00<?, ?B/s]
Loading pipeline components...: 0%| | 0/3 [00:00<?, ?it/s]
Sample
Finally, it’s time to run the denoising loop with the 4-bit Transformer model. At the end of the denoising loop, it returns latent embeddings which we can turn back into an image using the 4-bit VAE.
Note that the Flux pipeline has more arguments than the ones we pass here, see the docs for more info + API reference.
print(“Running denoising.”) height, width = 512, 768 images = pipeline( prompt_embeds=prompt_embeds, pooled_prompt_embeds=pooled_prompt_embeds, num_inference_steps=50, guidance_scale=5.5, height=height, width=width, output_type=”pil”, ).images images[0].save(“output.png”)
Running denoising.
0%| | 0/50 [00:00<?, ?it/s]
Let’s visualize the resulting image:
from PIL import Image Image.open(“output.png”)

Credits: NielsRogge